Como Escalar Automatizações de IA para Empresas com n8n e Ollama

TL;DR (Resumo Rápido)
- O que faz: Cria fluxos de trabalho empresariais automatizados conectando a ferramenta n8n a modelos de linguagem locais rodando no Ollama, sem custos com APIs externas.
- Principal Vantagem: Permite rodar agentes autônomos offline com total privacidade de dados, eliminando taxas de uso de nuvem e protegendo segredos comerciais da empresa.
- Acesso Direto: Comece instalando o Ollama Local e integrando com sua instância n8n Workflow.
À medida que as empresas adotam inteligência artificial para otimizar suas operações diárias, muitas se deparam com dois grandes obstáculos: custos de API imprevisíveis e segurança de dados corporativos. Enviar dados confidenciais de clientes, contratos e estratégias internas para servidores terceirizados pode violar leis de privacidade (como a LGPD) e abrir vulnerabilidades de segurança indesejadas.
Ao mesmo tempo, pagar centenas de dólares por milhões de tokens processados por modelos em nuvem pode inviabilizar projetos de automação em larga escala.
Felizmente, a resposta para esses problemas está na computação local. Unindo a flexibilidade da plataforma de automação n8n à potência do servidor de IA local Ollama, empresas de qualquer tamanho podem estruturar agentes autônomos rodando 100% offline, de forma segura e com custo zero de infraestrutura de nuvem.
O que é a Stack n8n + Ollama?
A stack n8n + Ollama combina o melhor de dois mundos: automação avançada baseada em nós e modelos de linguagem locais.
n8n (Workflow Automation)
O n8n é uma ferramenta de automação de fluxo de trabalho extensível e de código aberto. Ele permite que você conecte diferentes serviços, APIs e bancos de dados de forma visual. O grande diferencial do n8n é o seu suporte nativo ao desenvolvimento de agentes de IA complexos, incluindo nós dedicados a cadeias de raciocínio (Chains), memória persistente, agentes baseados em ferramentas e muito mais.
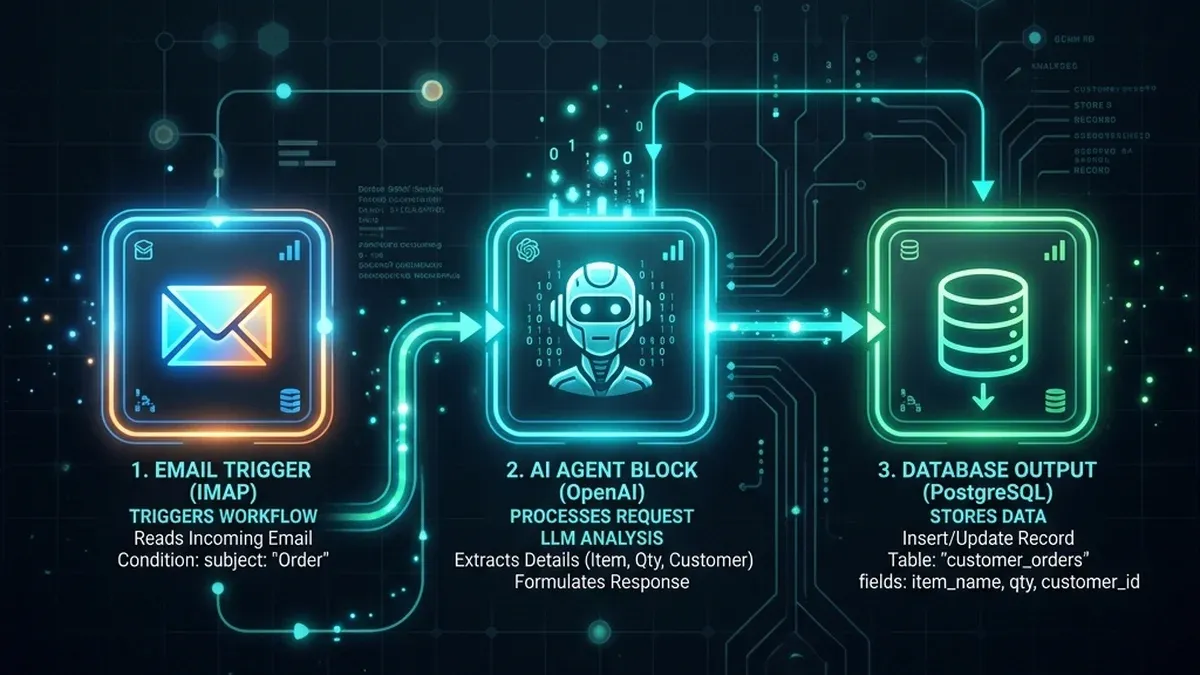
Ollama (LLMs Locais)
O Ollama é uma ferramenta leve que permite empacotar e executar grandes modelos de linguagem (como Llama 3, Mistral, Qwen e Gemma) diretamente no seu computador ou servidor local. Ele abstrai toda a complexidade de configurar drivers de GPU e dependências, oferecendo uma API simples que responde em localhost.
Por que Usar IA Local em Automações Empresariais?
A migração de APIs comerciais (como as da OpenAI ou Anthropic) para soluções locais rodando no Ollama brings benefícios estratégicos cruciais:
- Privacidade Absoluta (LGPD Compliance): Toda a informação processada permanece dentro da rede local da empresa. Se você automatiza a leitura de contratos médicos, faturas financeiras ou dados cadastrais, nenhum byte é exposto para servidores de terceiros.
- Custo Zero por Token: O custo de processamento se resume à energia elétrica consumida pela máquina local. Não importa se você processa 100 ou 100.000 requisições por dia, a fatura de tokens é inexistente.
- Independência de Conexão: Suas automações continuam funcionando mesmo se a internet oscilar ou se o serviço de nuvem internacional sofrer interrupções temporárias.
- Flexibilidade de Hardware: Você pode rodar modelos menores (como o Llama 3 8B) em computadores corporativos comuns equipados com processador rápido e pelo menos 16GB de RAM, ou escalar para hardware dedicado (como GPUs Nvidia RTX) para automações de altíssima velocidade.
Configurando a Automação: Passo a Passo Prático
Configurar o ecossistema local do n8n com o Ollama é um processo simples. Abaixo, detalhamos o roteiro para ativar esse ambiente no seu sistema:
Passo 1: Inicialize o Ollama e Baixe o Modelo
Baixe e instale o instalador do site oficial do Ollama. Abra o terminal do seu computador e execute o comando abaixo para baixar e rodar o modelo Llama 3:
ollama run llama3Esse comando faz o download automático dos arquivos do modelo e inicia um servidor local respondendo na porta padrão 11434.
Passo 2: Configure o n8n
Você pode rodar o n8n localmente usando Docker. O comando padrão para subir a imagem com as ferramentas de IA ativas é:
docker run -it --rm --name n8n -p 5678:5678 n8nio/n8nPasso 3: Conecte o n8n au Ollama
Ao criar um fluxo de IA no n8n (usando o nó AI Agent ou Basic LLM Chain), adicione o nó do modelo Ollama e preencha as configurações de conexão:
- Base URL:
http://localhost:11434(ou o IP do computador onde o Ollama está rodando na mesma rede) - Model:
llama3(ou o nome do modelo que você instalou)
Casos de Uso Reais para Empresas
A combinação de n8n e Ollama permite que negócios automatizem tarefas repetitivas com alta complexidade intelectual. Aqui estão os cenários corporativos onde essa stack mais se destaca:
Extração de Dados Estruturados de Documentos
Você pode receber arquivos PDF (como faturas ou currículos), enviá-los ao modelo de IA local e pedir para extrair informações específicas em formato JSON estruturado.
[!TIP] Se a sua empresa lida com um grande volume de documentos bagunçados que precisam ser unificados antes do processamento pela IA, utilize a nossa ferramenta local PDF Forge para agrupar e organizar seus PDFs de forma rápida e segura. Se precisar otimizar o esquema JSON para indexação correta no seu banco de dados, use o Schema Forge.
Triagem de Tickets de Suporte e E-mails
Configure um gatilho no n8n para ler novos e-mails recebidos. A IA local analisa o texto, classifica o sentimento do cliente, categoriza o assunto (ex: Financeiro, Técnico, Comercial) e rascunha a melhor resposta antes de repassar a tarefa para o atendente humano.
Geração Automatizada de Descrições de Produtos e SEO
Para e-commerces com milhares de produtos, a IA local pode ler as características técnicas cruciais e reescrevê-las em textos comerciais de alta conversão, gerando simultaneamente as tags e hashtags ideais de atração de tráfego. Para apoiar nesse processo, use o SEO & Tag Forge.
Comparativo: APIs Proprietárias vs. IA Local (Ollama)
| Característica | APIs Comerciais (OpenAI / Anthropic) | IA Local (n8n + Ollama) |
|---|---|---|
| Custo Inicial | Zero (apenas cadastro) | Médio (custo com hardware local) |
| Custo Recorrente | Variável (por volume de tokens processados) | Zero (apenas energia) |
| Privacidade | Depende de termos de uso em nuvem de terceiros | Absoluta (dados nunca saem da empresa) |
| Execução Offline | Não (requer internet estável) | Sim (roda 100% offline) |
Conclusão: Inteligência Artificial ao Alcance de Todos
Adotar n8n e Ollama representa a democratização do uso de inteligência artificial de ponta nos negócios. Em vez de ficar vulnerável à oscilação de preços de grandes corporações de tecnologia estrangeiras e a riscos regulatórios de segurança de dados, a sua empresa assume o controle total sobre sua infraestrutura e seus dados.
Essa flexibilidade permite criar um ambiente de automação extremamente escalável e produtivo, otimizando o tempo dos colaboradores em tarefas repetitivas e liberando a equipe para focar no crescimento estratégico.
Se você quer aprender mais sobre a lógica prática de negócios e como planejar a integração de IAs de verdade no seu micronegócio sem depender de estruturas gigantescas, não deixe de iniciar a leitura do nosso Ebook interativo IA Prática 1.0.