Como Criar Agentes de IA Autônomos de Graça com n8n e Ollama

TL;DR (Resumo Rápido)
- O que faz: Cria fluxos de trabalho inteligentes onde agentes de IA tomam decisões e executam ações reais (ler e-mails, salvar dados) localmente e de graça.
- Principal Vantagem: Custo zero de API e privacidade absoluta (LGPD), já que todos os dados e modelos de IA rodam offline na sua própria máquina.
- Acesso Direto: Instale o Ollama Local e o n8n no Docker seguindo os comandos práticos abaixo.
A era dos simples chatbots que apenas respondem perguntas está chegando ao fim. Em 2026, a grande tendência que está dominando as buscas é a IA Agêntica (ou Agentes de IA Autônomos). Diferente de um assistente passivo, um agente autônomo é capaz de planejar etapas, interagir com ferramentas externas (como bancos de dados e APIs), tomar decisões lógicas e executar fluxos de trabalho completos sem a necessidade de intervenção humana constante.
No entanto, criar esses agentes usando APIs pagas na nuvem (como OpenAI ou Anthropic) pode se tornar extremamente caro e expõe dados corporativos ou pessoais sensíveis a servidores de terceiros.
A solução definitiva e 100% gratuita para esse problema é a combinação do n8n (plataforma visual de automação) com o Ollama (servidor de modelos de linguagem local). Neste guia passo a passo, você aprenderá a configurar esse ecossistema do absoluto zero.
O que é a Stack n8n + Ollama?
Essa arquitetura se consolidou como o padrão ouro para desenvolvedores e empresas que buscam autonomia tecnológica. Ela é composta por duas ferramentas principais:
- n8n: Uma ferramenta de automação avançada baseada em fluxos de trabalho visuais. A versão mais recente do n8n traz nós nativos de IA (Advanced AI) baseados no ecossistema LangChain. Isso permite construir agentes com memória persistente, encadeamento de raciocínio e ferramentas de ação de forma simples.
- Ollama: Um servidor leve e otimizado que roda modelos de linguagem de código aberto (como Llama 3, Mistral, Qwen e Gemma) diretamente no processador ou na placa de vídeo (GPU) do seu computador. Ele gerencia os modelos e expõe uma API simples que responde em
localhost.
Passo 1: Instalando e Configurando o Ollama Localmente
O Ollama simplifica o processo de rodar grandes modelos de linguagem (LLMs) localmente. Ele suporta aceleração por GPU de forma automática no Windows, macOS e Linux.
- Acesse o site oficial do Ollama e faça o download para o seu sistema operacional.
- Após a instalação, abra o terminal do seu sistema (Prompt de Comando ou PowerShell no Windows) e execute o comando abaixo para baixar e rodar o modelo Llama 3:
ollama run llama3- O Ollama fará o download do modelo (aproximadamente 4.7 GB para a versão de 8 bilhões de parâmetros) e iniciará um chat interativo no próprio terminal.
- O servidor do Ollama ficará rodando em segundo plano no endereço
http://localhost:11434. Você pode fechar o terminal do chat, mas mantenha o ícone do Ollama active na barra de tarefas.
Passo 2: Subindo o n8n via Docker
A maneira mais estável e rápida de rodar o n8n localmente com suporte completo a integrações locais é utilizando o Docker.
- Certifique-se de que o Docker Desktop está instalado e rodando em sua máquina.
- Abra o terminal e execute o seguinte comando para iniciar o contêiner do n8n:
docker run -it --rm --name n8n -p 5678:5678 -e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true n8nio/n8n📝 Nota: Se você estiver utilizando o Docker no Windows/macOS e quiser que o contêiner do n8n se conecte ao Ollama que roda no host (sua máquina física), use o endereço
http://host.docker.internal:11434em vez delocalhostnas configurações.
- Acesse
http://localhost:5678no seu navegador para abrir a interface do n8n, crie sua conta de administrador local e você estará pronto para criar seu primeiro fluxo.
Passo 3: Construindo o Agente Autônomo no n8n
Para demonstrar a força da IA Agêntica, vamos estruturar um agente que recebe instruções, decide quais ferramentas usar para resolver uma tarefa e entrega o resultado final.
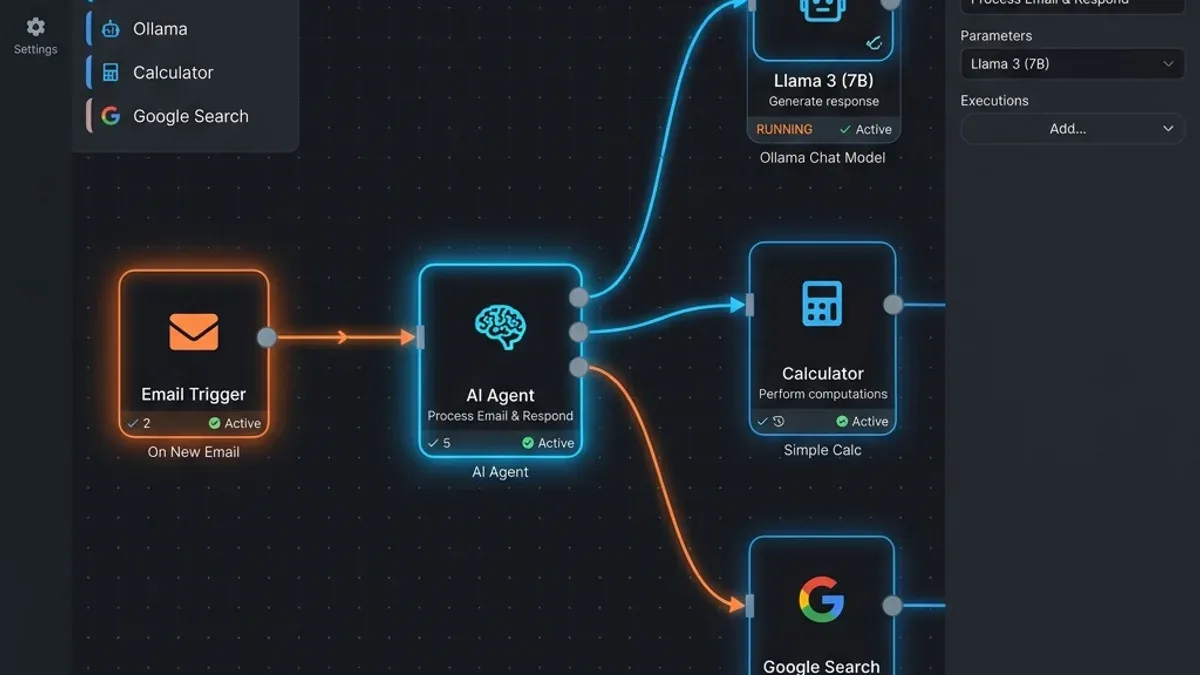
1. Crie um Novo Workflow
No n8n, clique em Add Workflow. Adicione o nó principal chamado AI Agent. Esse nó centraliza o raciocínio do agente.
2. Conecte o Modelo de Linguagem (Ollama)
No campo correspondente ao modelo de chat no nó AI Agent, adicione o nó Ollama Chat Model.
- Base URL: Insira
http://host.docker.internal:11434(se estiver no Docker) ouhttp://localhost:11434. - Model: Digite exatamente
llama3(ou outro modelo que você tenha baixado no Ollama).
3. Adicione Ferramentas (Tools) ao Agente
Agentes autônomos só conseguem interagir com o mundo real através de ferramentas. No nó do AI Agent, conecte ferramentas na seção Tools:
- Calculator: Para permitir que a IA execute operações matemáticas complexas sem errar.
- Wikipedia or Google Search Tool: Para permitir que a IA busque fatos recentes na internet caso o modelo local não saiba.
- Custom HTTP Request Node: Para fazer chamadas de API personalizadas, como ler e-mails ou enviar mensagens.
4. Configure a Memória do Agente
Conecte o nó Window Buffer Memory na entrada de memória do agente. Isso garante que ele se lembre do contexto da conversa e das etapas anteriores que executou.
Exemplo de Fluxo: Triagem Automática de E-mails e Atualização de Faturas
Imagine o seguinte cenário automatizado rodando na sua máquina:
- Gatilho (Trigger): O n8n monitora sua caixa de entrada de e-mails a cada 5 minutos.
- Raciocínio (AI Agent): O e-mail recebido é enviado para o Llama 3 local via Ollama. O agente analisa o conteúdo e decide:
- Se for uma cobrança: Ele usa uma ferramenta HTTP para extrair os dados da fatura e salvar em uma planilha local.
- Se for uma dúvida de cliente: Ele rascunha uma resposta com base nas diretrizes da empresa salvas em um documento de texto local.
- Ação: O n8n envia a resposta para aprovação ou atualiza a planilha automaticamente.
💡 Dica: Se as faturas ou relatórios da sua empresa forem recebidos em arquivos PDF bagunçados ou fragmentados, você pode organizá-los e mesclá-los localmente antes do processamento usando o PDF Forge. Para garantir a segurança dos dados gerados nas planilhas, use o KeyForge para criar chaves de criptografia e senhas de acesso locais.
Comparativo: IA Local vs. APIs Pagas na Nuvem
| Critério | APIs Proprietárias (OpenAI / Claude) | Stack Local (n8n + Ollama) |
|---|---|---|
| Custo por 1M de Tokens | De US$ 5.00 a US$ 15.00 | R$ 0,00 (apenas energia do PC) |
| Privacidade dos Dados | Dados enviados para servidores externos | Absoluta (dados não saem da máquina) |
| Dependência de Internet | 100% dependente de conexão estável | Roda offline ou em rede local isolada |
| Velocidade | Rápida (servidores de alta performance) | Depende da GPU/Processador local |
Conclusão: Domine a Automação Inteligente
Configurar agentes autônomos locais com n8n e Ollama permite que qualquer profissional ou empresa crie soluções de produtividade robustas sem ficar refém das assinaturas e mudanças repentinas de preços das Big Techs. Você ganha total controle sobre a segurança dos dados, conformidade com a LGPD e escala suas automações sem se preocupar com a conta de tokens no fim do mês.
Se você deseja se aprofundar na lógica de negócios automatizados por IA, entender como mapear processos operacionais e implementar automações práticas no seu dia a dia sem complicações, comece a ler o nosso e-book prático e interativo IA Prática 1.0.